Look inside ImageDataLoaders
what is it? what's in it? Let's dig more inside of this handy class by looking inside of the actual source code.
- Why looking inside?
- Let's see the definition
- Let's look inside one of them, from_folder(...)
- GrandparentSplitter function
- partial( get_image_files, folders=[train, valid] )
- DataBlock
Why looking inside?
There is a couple of reasons. First, fastai is a wonderful library. It clearly shows how it works in a high-level view. However, when you want to customize its behaviour, the official document is somewhat limited to understand behind scene. Second, fastai comes along with other awesome libraries such as fastcore. You will find very useful and clever programming usage with them. Also it helps you to have strong programability.
Let's see the definition
Basic wrapper around several DataLoaders with factory methods for computer vision problems. Don't be bothered by delegates thing for now. I will explain what it is shortly.
In a nutshell, ImageDataLoaders provides a set of handy class methods to define a set of datasets to be fed into a model. As the plural form of the name indicates, it contains more than one dataset which means multiple datasets such as training/validation/test could be managed in one place.
class ImageDataLoaders(DataLoaders):
@classmethod
@delegates(DataLoaders.from_dblock)
def from_folder(...)
@classmethod
@delegates(DataLoaders.from_dblock)
def from_path_func(...)
@classmethod
def from_name_func(...)
@classmethod
def from_path_re(...)
@classmethod
@delegates(DataLoaders.from_dblock)
def from_name_re(...)
@classmethod
@delegates(DataLoaders.from_dblock)
def from_df(...)
@classmethod
def from_csv(...)
@classmethod
@delegates(DataLoaders.from_dblock)
def from_lists(...)
 [ ImageDataLoaders.from_path_func ]
[ ImageDataLoaders.from_path_func ]
The name of each class methods explains itself pretty much. However, just remember, those suffixes _xxx simply means how you would like to define labels for each data. For instance, from_folder defines labels of each data by looking up the name of folders. from_path_func provides more flexible way than from_folder. Instead of specifying the folder name, we can actually write a function to extract which part of the path name should be used for labeling.
- with
from_folder, the directory structure should strictly follow like below (the folder name for training/validation could be changed).- top_director - training - validation - when the directory structure is like below,
from_foldercan't be used. But you could parse the part of path name to be used as labels viafrom_path_func.- top_directory - training - training - validation - validation- this examples looks silly, but you will soon realize there are many datasets structured in this way. You could either move the files into the parent directory or just simply use
from_path_func.
- this examples looks silly, but you will soon realize there are many datasets structured in this way. You could either move the files into the parent directory or just simply use
Another cool method is from_path_re. It lets you to define labels by leveraging the power of regular expression. Even though you could implement your own regex paring logic in from_path_func, you could avoid from somewhat annoying boilerplates to set up regex with from_path_re.
Each methods
This cell provides a complete description of each class methods scrapped from the official document.
-
from_folder(...)
- Create from imagenet style dataset in
pathwithtrainandvalidsubfolders (or providevalid_pct)
- Create from imagenet style dataset in
-
from_path_func(...)
- Create from list of
fnamesinpaths withlabel_func
- Create from list of
-
from_name_func(...)
- Create from the name attrs of
fnamesinpaths withlabel_func
- Create from the name attrs of
-
from_path_re(...)
- Create from list of
fnamesinpaths with re expressionpat
- Create from list of
-
from_name_re(...)
- Create from the name attrs of
fnamesinpaths with re expressionpat
- Create from the name attrs of
-
from_df(...)
- Create from
dfusingfn_colandlabel_col
- Create from
-
from_csv(...)
- Create from
path/csv_fnameusingfn_colandlabel_col
- Create from
-
from_lists(...)
- Create from list of
fnamesandlabelsinpath
- Create from list of
Example usage with from_path_func
The example below is borrowed from fastai official document.
path = 'top directory'
fnames = 'list of files'
def label_func(x):
return x.parent.name
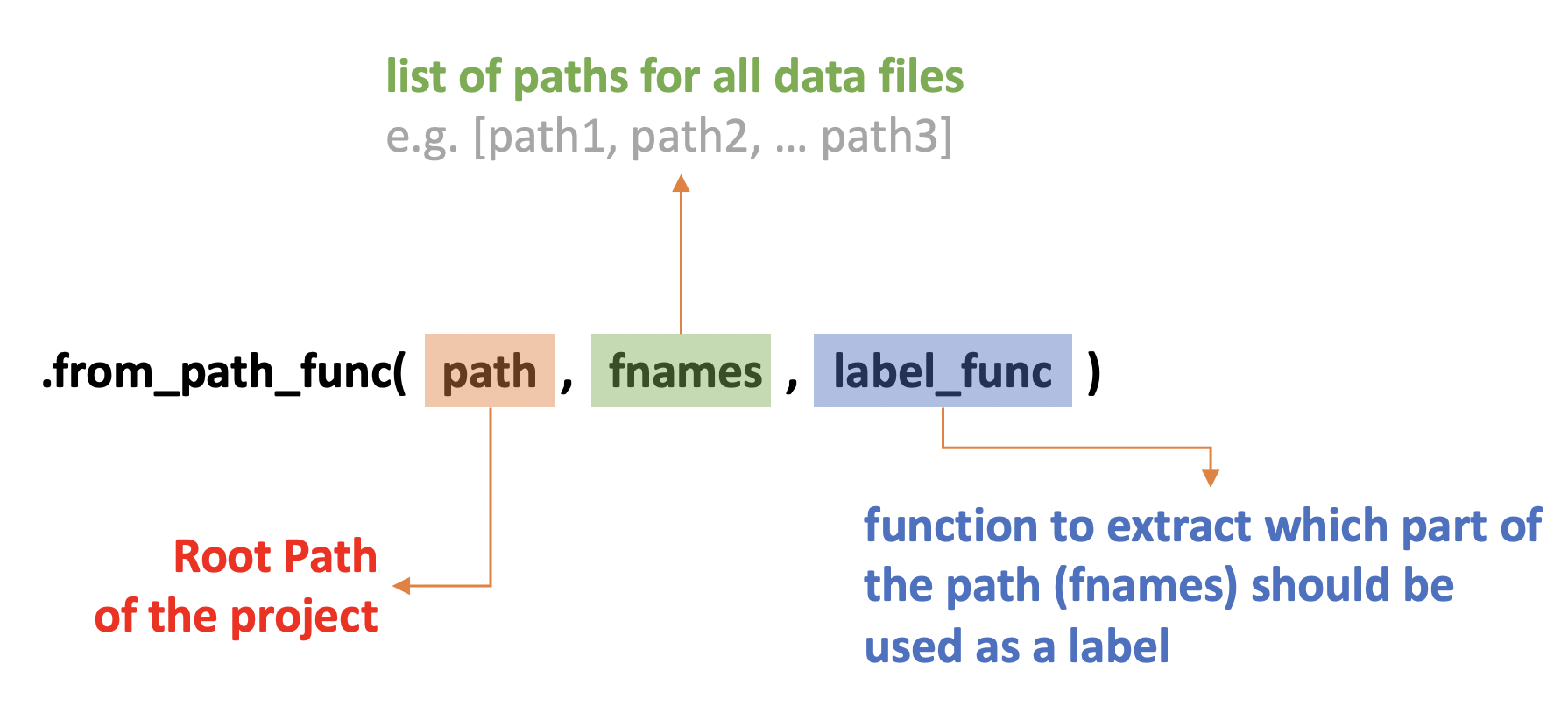
dls = ImageDataLoaders.from_path_func(path = path,
fnames = fnames,
label_func = label_func)
from_path_func takes three parameters. The path is the path of the root directory of the project. fnames is a list containing all data files. It doesn't matter to include files stored in different sub-directories. Which file should belong to which label is determined via 1abel_func function .
Let's look inside the label_func function. It is clear that it returns the name of the parent directory. For instance, if the path of a file is like datasets/train/image1.png, the label func will return train as the label for the image1.png.
@classmethod
@delegates(DataLoaders.from_dblock)
def from_folder(cls, path,
train='train', valid='valid',
valid_pct=None, seed=None, vocab=None,
item_tfms=None, batch_tfms=None, **kwargs):
splitter = GrandparentSplitter(train_name=train, valid_name=valid) \
if valid_pct is None \
else RandomSplitter(valid_pct, seed=seed)
get_items = get_image_files \
if valid_pct \
else partial(get_image_files, folders=[train, valid])
dblock = DataBlock(blocks=(ImageBlock, CategoryBlock(vocab=vocab)),
get_items=get_items,
splitter=splitter,
get_y=parent_label,
item_tfms=item_tfms,
batch_tfms=batch_tfms)
return cls.from_dblock(dblock, path, path=path, **kwargs)
GrandparentSplitter function
 [ what does GrandparentSplitter really returns? ]
[ what does GrandparentSplitter really returns? ]
GrandparentSplitter is a function that returns diffrent function. It's like you call a function, then you get another function from that call. The returning function is defined as _inner, but when you assign the returning function to a variable, that variable's name becomes the actual function name.
my_func = GrandparentSplitter()
my_func(...)
In the above example code, even though the defined function name is _inner, the variable name, my_func delegates the function _inner.
So, what GrandparentSplitter really does is to return another function. I will call it as G._inner for convinience. So, the real question gets down to what's the job of G._inner function.
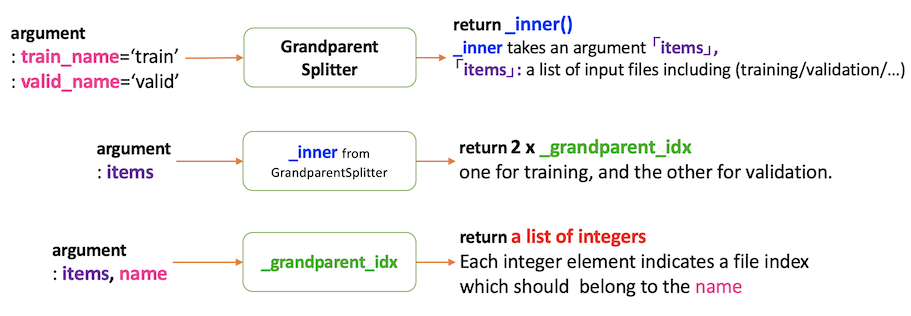
def _grandparent_idxs(items, name):
def _inner(items, name):
return mask2idxs(Path(o).parent.parent.name == name for o in items)
return [i for n in L(name) for i in _inner(items,n)]
def GrandparentSplitter(train_name='train', valid_name='valid'):
"Split `items` from the grand parent folder names (`train_name` and `valid_name`)."
def _inner(o):
return _grandparent_idxs(o, train_name),_grandparent_idxs(o, valid_name)
return _inner
G._inner takes only one argument, o. However, it uses parameters passed from GrandparentSplitter as well. That is something called as closer. If you are interested in, please search for it.
Don't be bothered by the argument name o in G._inner. It simply means items, and the items here means every files, trainining or validation data files are listed up together.
Now, G._inner returns two functions of the same type, _grandparent_idxs. Because when we call GrandparentSplitter, it will return G._inner, and when G._inner is called, it will return two _grandparent_idxs functions, the behaviour of _grandparent_idxs is what we really want to know.
my thoughts
-
GrandparentSplitteris nothing but a utility function to provide another function to let you grasp the list of indicies for training and validation datasets. - We can create our own splitter. It is quite simple.
- define a function
- make sure the function returns two sets of lists
- make sure each list contains indicies of files (not the filename or something)
- use handy
mask2idxfunction to filter which file belongs to which dataset
I should also mention about mask2idx function. It takes a list of booleans, and it returns a list of integers which indicate the index where the boolean value is True. So this is exactly what we need to get the list of indicies!
In order to understand this part, you should understand what partial is first. partial is a great way to define a new function derived from an existing one by substituting values of arguments.
Below shows what get_image_files function looks like:
def get_image_files(path, recurse=True, folders=None):
"Get image files in `path` recursively, only in `folders`, if specified."
return get_files(path, extensions=image_extensions, recurse=recurse, folders=folders)
As you can see, get_image_files has trhee arguments including folders whose default value is None. However, when we do new_func = partial( get_image_files, folders=[train, valid] ) this, it returns a new form of function like
def get_image_files(path, recurse=True):
"Get image files in `path` recursively, only in `folders`, if specified."
return get_files(path, extensions=image_extensions, recurse=recurse, folders=[train, valid])
From this point, we just can call new_func() without passing values into folders anymore.
why need partial?
- Remember
partialgives you a new template of a function. It doesn't call the function with different values. Withoutpartialwe should explicitly call the function with specific values where we actually need to call. Lots of conditionaly statements may be required.
get_image_files
get_image_files gets all image type files under specified folders. It recursively collectes files in the sub-directories as well. The targeting image file extensions are all image types defined in memetypes. The following block shows what are they:
types_map = { # from Python's official source file
# https://svn.python.org/projects/python/trunk/Lib/mimetypes.py
'.bmp' : 'image/x-ms-bmp',
'.gif' : 'image/gif',
'.ief' : 'image/ief',
'.jpe' : 'image/jpeg',
'.jpeg' : 'image/jpeg',
'.jpg' : 'image/jpeg',
'.pbm' : 'image/x-portable-bitmap',
'.pgm' : 'image/x-portable-graymap',
'.png' : 'image/png',
'.pnm' : 'image/x-portable-anymap',
'.ppm' : 'image/x-portable-pixmap',
'.ras' : 'image/x-cmu-raster',
'.rgb' : 'image/x-rgb',
'.tif' : 'image/tiff',
'.tiff' : 'image/tiff',
'.xbm' : 'image/x-xbitmap',
'.xpm' : 'image/x-xpixmap',
'.xwd' : 'image/x-xwindowdump',
}
In get_image_files(folders=['train', 'valid']) case, it looks for every image files under train and valid folders, and return the list of identified image files.
DataBlock
DataBlock is the core to make datasets feedable into a model. The inside source code is pretty long.
@funcs_kwargs
class DataBlock():
"Generic container to quickly build `Datasets` and `DataLoaders`"
get_x = get_items = splitter = get_y = None
_methods = 'get_items splitter get_y get_x'.split()
blocks,dl_type = (TransformBlock,TransformBlock),TfmdDL
def __init__(self, blocks=None, dl_type=None, getters=None,
n_inp=None,
item_tfms=None, batch_tfms=None,
**kwargs):
blocks = L(self.blocks if blocks is None else blocks)
blocks = L(b() if callable(b) else b for b in blocks)
self.type_tfms = blocks.attrgot('type_tfms', L())
self.default_item_tfms = _merge_tfms(*blocks.attrgot('item_tfms', L()))
self.default_batch_tfms = _merge_tfms(*blocks.attrgot('batch_tfms', L()))
for b in blocks:
if getattr(b, 'dl_type', None) is not None: self.dl_type = b.dl_type
if dl_type is not None: self.dl_type = dl_type
self.dataloaders = delegates(self.dl_type.__init__)(self.dataloaders)
self.dls_kwargs = merge(*blocks.attrgot('dls_kwargs', {}))
self.n_inp = ifnone(n_inp, max(1, len(blocks)-1))
self.getters = ifnone(getters, [noop]*len(self.type_tfms))
if self.get_x:
if len(L(self.get_x)) != self.n_inp:
raise ValueError(f'...')
self.getters[:self.n_inp] = L(self.get_x)
if self.get_y:
n_targs = len(self.getters) - self.n_inp
if len(L(self.get_y)) != n_targs:
raise ValueError(f'...')
self.getters[self.n_inp:] = L(self.get_y)
if kwargs: raise TypeError(f'...')
self.new(item_tfms, batch_tfms)
Let's see lines by lines
@funcs_kwargs
@funcs_kwargs
class DataBlock():
get_x = get_items = splitter = get_y = None
_methods = 'get_items splitter get_y get_x'.split()
@funcs_kwargs is a decorator defined in fastcore library. When it is set, we can pass a function in a constructor, and that function becomes the class member method. Which function to be allowed is defined in _methods property. _methods property is just a list of string representing function names to be added via constructor.
Consider this. As you see, class Calc doesn't have a method named minus yet in its definition time.
@func_kwargs
class Calc():
_methods = ['minus']
def __init__(self, **kwargs): pass
def plus(self, x, y): return x+y
However, we can simply add minus function defined outside of the Calc class later and specify as we want it to become a class member method via the constructor.
def minus(x, y): return x-y
calc = Calc(minus=minus)
calc.minus(10, 7)
Let's recall that there is **kwargs argument in __init__ function of DataBlock class. And also, let's recall we have passed arguments that are not explicitly defined in __init__ function when instantiating DataBlock object in from_folder function such as splitter, get_x, get_y, and get_items.
You probably noticed by now that all those functions are specified in __methods property. When instantiating DataBlock object, it is going to have splitter, get_x, get_y, and get_items as member methods. Without @func_kwargs, we may end up by defining too many class like grandparent, parent, child, .....
Initial setup for blocks
blocks,dl_type = (TransformBlock,TransformBlock),TfmdDL
def __init__(...):
blocks = L(self.blocks if blocks is None else blocks)
blocks = L(b() if callable(b) else b for b in blocks)
...
These three lines of code simply re-arrange the contents inside blocks in two steps.
- first, default value for
blocksis set as(TransformBlock,TransformBlock) - if nothing is passed into
blocksargument in__init__, it will use just defaultblocks. If not, use the specifiedblocksinstead. -
blocksis a tuple, and there could be an arbitrary number of elements in it. Each element could be not only a class type but also a function type. If any is a function type, it will be replaced by its returning value.
We have specified blocks=(ImageBlock, CategoryBlock(vocab=vocab) in from_folder method. ImageBlock and CategoryBlock are functions, and each one returns TransformBlock object with different setting. So after two lines of code in __init__, the actual blocks content should be like (TransformBlock, TransformBlock)
At this point, we can notaice that function is not the only way. If we want more complex logics, we can subclass TransformBlock and define complex behaviour in it.
def ImageBlock(cls=PILImage):
"A `TransformBlock` for images of `cls`"
return TransformBlock(type_tfms=cls.create, batch_tfms=IntToFloatTensor)
def CategoryBlock(vocab=None, sort=True, add_na=False):
"`TransformBlock` for single-label categorical targets"
return TransformBlock(type_tfms=Categorize(vocab=vocab, sort=sort, add_na=add_na))
separately store item_tfms and batch_tfms
def __init__(...):
...
self.type_tfms = blocks.attrgot('type_tfms', L())
self.default_item_tfms = _merge_tfms(*blocks.attrgot('item_tfms', L()))
self.default_batch_tfms = _merge_tfms(*blocks.attrgot('batch_tfms', L()))
...
We saw blocks is just a list. Now precisely!. It is actually a type L. L is a new data structure developed in fastai as a part of fastcore project. L and list are compatible, but L comes along with useful add-on methods.
attrgot is one of them. attrgot method looks for every element in the list, and when any element has a specified attribute, it pulls out only that attribute and create a new list with those attribute. For instance, blocks.attrgot('type_tfms', L()) simply says to get the value of type_tfms attribute in each element and create a new L with them. If no element has that attribute, just give me an empty L().
The same thing happens for default_item_tfms and default_batch_tfms as well. There is just one more thing _merge_tfms.
def __init__(...):
...
for b in blocks:
if getattr(b, 'dl_type', None) is not None: self.dl_type = b.dl_type
...
def __init__(...):
...
if dl_type is not None: self.dl_type = dl_type
self.dataloaders = delegates(self.dl_type.__init__)(self.dataloaders)
self.dls_kwargs = merge(*blocks.attrgot('dls_kwargs', {}))
...
def __init__(...):
...
self.n_inp = ifnone(n_inp, max(1, len(blocks)-1))
self.getters = ifnone(getters, [noop]*len(self.type_tfms))
...
def __init__(...):
...
if self.get_x:
if len(L(self.get_x)) != self.n_inp:
raise ValueError(f'...')
self.getters[:self.n_inp] = L(self.get_x)
...
def __init__(...):
...
if self.get_y:
n_targs = len(self.getters) - self.n_inp
if len(L(self.get_y)) != n_targs:
raise ValueError(f'...')
self.getters[self.n_inp:] = L(self.get_y)
...
def __init__(...):
...
if kwargs: raise TypeError(f'...')
self.new(item_tfms, batch_tfms)
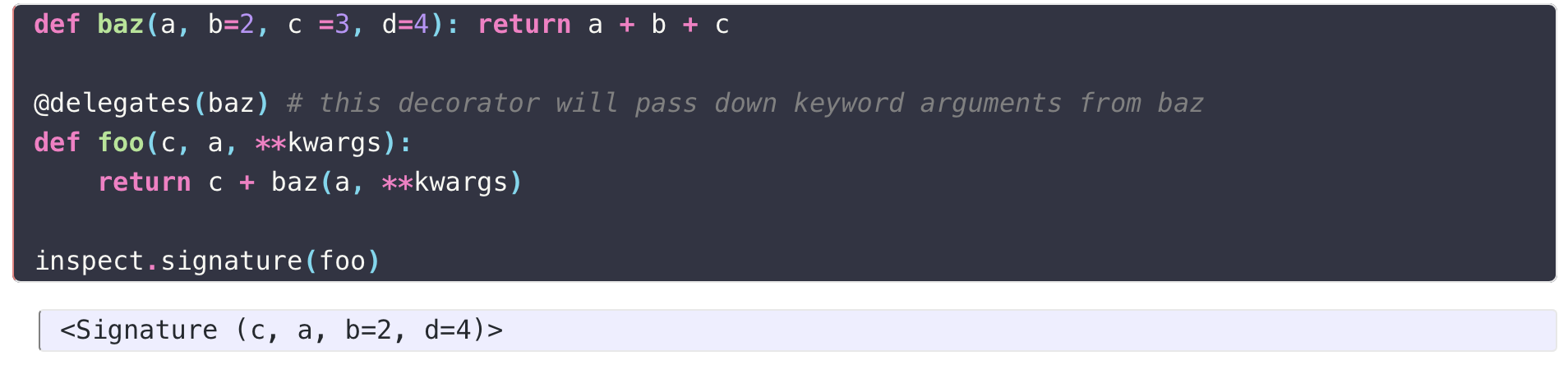
@delegates is a decorator from fastcore package. It delegates all the parameters/arguments from a function specified in (...). It even covers **kwargs.
- If you actually print out
from_folder,**kwargsthings will be revealed/demystified. - please look at the picture below borrowed from fastcore: An Underrated Python Library by Hamel Husain